Where do the stack traces come from?
 |
| Aker Brygge seen from a boat |
foo(), bar() or maybe both?public class Main {
public static void main(String[] args) throws IOException {
try {
foo();
} catch (RuntimeException e) {
bar(e);
}
}
private static void foo() {
throw new RuntimeException("Foo!");
}
private static void bar(RuntimeException e) {
throw e;
}
}
In C# both answers would be possible depending on how the original exception is re-thrown in bar() - throw e overwrites the original stack trace (originating in foo()) with the place where it was thrown again (in bar()). On the other hand bare "throw" keyword re-throws the exception keeping the original stack trace. Java follows the second approach (using the syntax of the first one) and doesn't even allow the former approach directly. But what about this slightly modified version:public static void main(String[] args) throws IOException {
final RuntimeException e = foo();
bar(e);
}
private static RuntimeException foo() {
return new RuntimeException();
}
private static void bar(RuntimeException e) {
throw e;
}
foo() only creates the exception, but instead of throwing, returns that exception object. This exception is then thrown from a completely different method. How will the stack trace look now? Surprise, it still points to foo(), just like if the exception was thrown from there, exactly the same as in first example:Exception in thread "main" java.lang.RuntimeExceptionWhat's going on, you might ask? Looks like the stack trace is not generated when the exception is thrown, but when the exception object is created. In a vast majority of situations these actions occur in the same place, so no one bothers. Many beginning Java programmers aren't even aware that one can create an exception object and assign it to a variable or field or even pass it around.
at Main.foo(Main.java:7)
at Main.main(Main.java:15)
But where does the exception stack trace come from, really? The answer is quite simple, from
Throwable.fillInStackTrace() method!public class Throwable implements Serializable {
public synchronized native Throwable fillInStackTrace();
//...
}
Notice that this method is not final, which allows us to hack a little bit. Not only we can bypass stack trace creation and throw an exception without any context, but even overwrite the stack completely!public class SponsoredException extends RuntimeException {
@Override
public synchronized Throwable fillInStackTrace() {
setStackTrace(new StackTraceElement[]{
new StackTraceElement("ADVERTISEMENT", " If you don't ", null, 0),
new StackTraceElement("ADVERTISEMENT", " want to see this ", null, 0),
new StackTraceElement("ADVERTISEMENT", " exception ", null, 0),
new StackTraceElement("ADVERTISEMENT", " please buy ", null, 0),
new StackTraceElement("ADVERTISEMENT", " full version ", null, 0),
new StackTraceElement("ADVERTISEMENT", " of the program ", null, 0)
});
return this;
}
}
public class ExceptionFromHell extends RuntimeException {
public ExceptionFromHell() {
super("Catch me if you can");
}
@Override
public synchronized Throwable fillInStackTrace() {
return this;
}
}
Throwing the exceptions above will result in the following errors printed by the JVM (seriously, try it!)Exception in thread "main" SponsoredExceptionThat's right.
at ADVERTISEMENT. If you don't (Unknown Source)
at ADVERTISEMENT. want to see this (Unknown Source)
at ADVERTISEMENT. exception (Unknown Source)
at ADVERTISEMENT. please buy (Unknown Source)
at ADVERTISEMENT. full version (Unknown Source)
at ADVERTISEMENT. of the program (Unknown Source)
Exception in thread "main" ExceptionFromHell: Catch me if you can
ExceptionFromHell is even more interesting. As it does not include the stack trace as part of the exception object, only class name and message are available. Stack trace was lost and neither JVM nor any logging framework can do anything about it. Why on earth would you ever do that (and I am not talking about SponsoredException)?Unexpectedly generating stack trace is considered expensive by some (?) It's a
native method and it has to walk down the whole stack to build the StackTraceElements. Once in my life I saw a library using this technique to make throwing exceptions faster. So I wrote a quick caliper benchmark to see the performance difference between throwing normal RuntimeException and exception without stack trace filled vs. ordinary method returning value. I run tests with different stack trace depths using recursion:public class StackTraceBenchmark extends SimpleBenchmark {
@Param({"1", "10", "100", "1000"})
public int threadDepth;
public void timeWithoutException(int reps) throws InterruptedException {
while(--reps >= 0) {
notThrowing(threadDepth);
}
}
private int notThrowing(int depth) {
if(depth <= 0)
return depth;
return notThrowing(depth - 1);
}
//--------------------------------------
public void timeWithStackTrace(int reps) throws InterruptedException {
while(--reps >= 0) {
try {
throwingWithStackTrace(threadDepth);
} catch (RuntimeException e) {
}
}
}
private void throwingWithStackTrace(int depth) {
if(depth <= 0)
throw new RuntimeException();
throwingWithStackTrace(depth - 1);
}
//--------------------------------------
public void timeWithoutStackTrace(int reps) throws InterruptedException {
while(--reps >= 0) {
try {
throwingWithoutStackTrace(threadDepth);
} catch (RuntimeException e) {
}
}
}
private void throwingWithoutStackTrace(int depth) {
if(depth <= 0)
throw new ExceptionFromHell();
throwingWithoutStackTrace(depth - 1);
}
//--------------------------------------
public static void main(String[] args) {
Runner.main(StackTraceBenchmark.class, new String[]{"--trials", "1"});
}
}
Here are the results: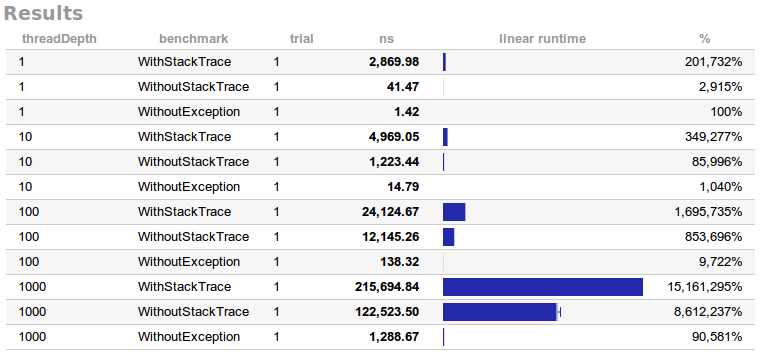
We can clearly see that the longer the stack trace is, the longer it takes to throw an exception. We also see that for reasonable stack trace lengths throwing an exception should not take more than 100 μs (faster than reading 1 MiB of main memory). Finally throwing an exception without stack trace is 2-5 times faster. But honestly, if this is an issue for you, the problem is somewhere else. If your application throws exceptions so often that you actually have to optimize it, there is probably something wrong with your design. Do not fix Java then, it's not broken.
Summary:
- stack trace always shows the place where the exception (object) was created, not where it was thrown - although in 99% of the cases that's the same place.
- you have full control over the stack trace returned by your exceptions
- generating stack trace has some cost, but if it becomes a bottleneck in your application, you are probably doing something wrong.
See also:
- Russian translation: Откуда берутся стектрейсы?