Remote actors - discovering Akka
Obviously every node in the cluster is independent, having its own, separate instance of Akka, thus a separate copy of
- The client application should call the URL [...] at most from one thread - it's forbidden to concurrently fetch random numbers using several HTTP connections.
RandomOrgClient actor. In order to fix this issue we have few options:- having a global (cluster-wide!) lock (distributed monitor, semaphore, etc.) guarding multithreaded access. Ordinary
synchronizedis not enough.
- ...or create a dedicated node in the cluster to communicate with
random.org, used by all other nodes via some API
- ...or create only one instance of
RandomOrgClienton exactly one node and expose it via some API (RMI, JMS...) to remote clients
Actor and ActorRef? Now this distinction will become obvious. In turns out our solution will be based on the last suggestion, however we don't have to bother about API, serialization, communication or transport layer. Even better, there is no such API in Akka to handle remote actors. It's enough to say in the configuration file: this particular actor is suppose to be created only on this node. All other nodes, instead of creating the same actor locally, will return a special proxy, which looks like a normal actor from the outside, while in reality it forwards all messages to remote actor on other node.Let's say it again: we don't have to change anything in our code, it's enough to make some adjustments in the configuration file:
akka {
actor {
provider = "akka.remote.RemoteActorRefProvider"
deployment {
/buffer/client {
remote = "akka://RandomOrgSystem@127.0.0.1:2552"
}
}
}
remote {
transport = "akka.remote.netty.NettyRemoteTransport"
log-sent-messages = on
netty {
hostname = "127.0.0.1"
}
}
}
That's it! Each node in the cluster is identified by the server address and port. Key part of the configuration is the declaration that /buffer/client is suppose to be created only 127.0.0.1:2552. Every other instance (working on a different server or port), instead of creating a new copy of the actor, will build a special transparent proxy, calling remote server.If you don't remember the architecture of our solution, figure below demonstrates the message flow. As you can see each node has its own copy of
RandomOrgBuffer (otherwise each access of the buffer would result in remote call, which defeats the purpose of the buffer altogether). However each node (except the middle one) has a remote reference to a RandomOrgClient actor (node in the middle accesses this actor locally):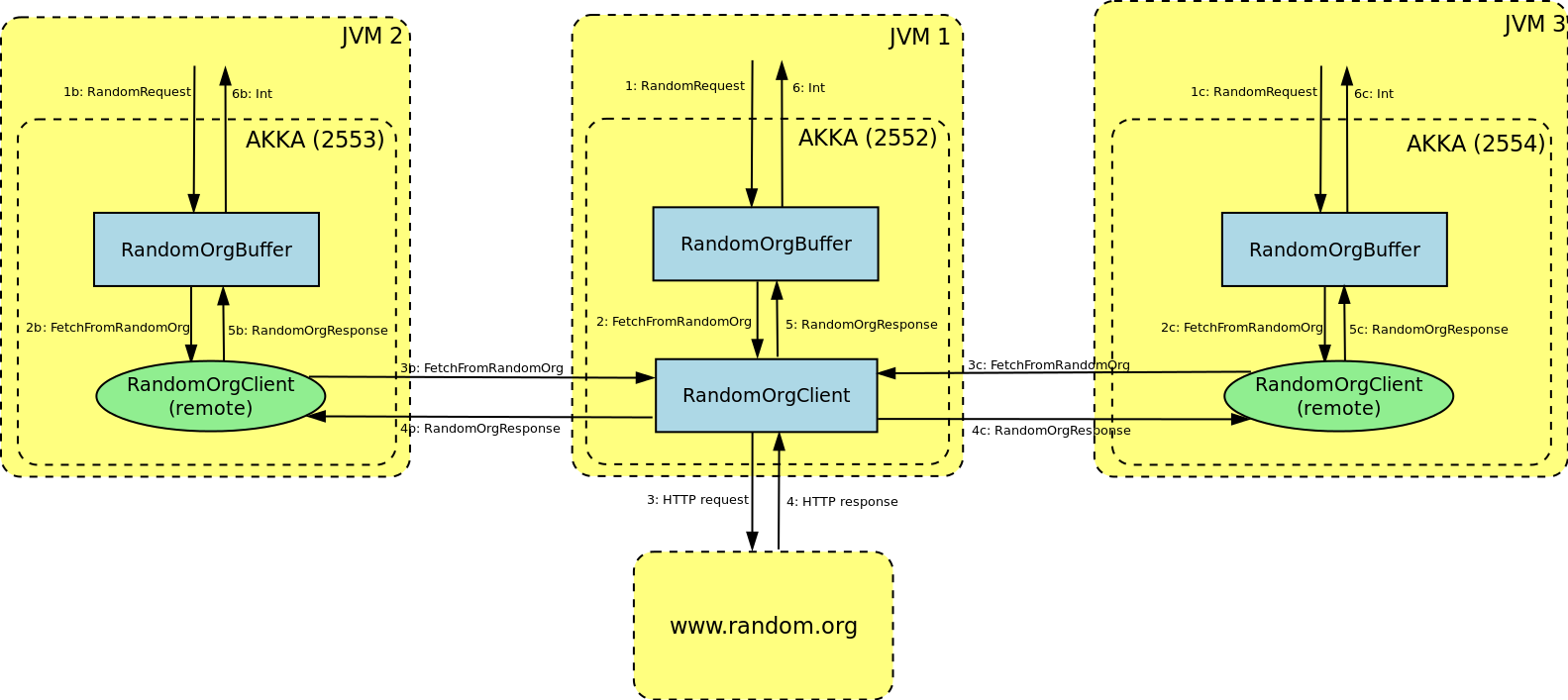
The machine in the middle (JVM 1) is executed on port 2552 and it's the only machine that communicates with
random.org. All the others (JVM 2 and 3 working on 2553 and 2554 respectively) are communicating with this server indirectly via JVM 1. BTW we can change the TCP/IP port used by each node either by using configuration file or -Dakka.remote.netty.port=2553 Java property.Before we announce premature success (again), we are faced with another problem. Or actually, we haven't really passed the original obstacle yet. Since
RandomOrgClient is now accessed by multiple RandomBuffer actors (distributed across the cluster), it can still initiate multiple concurrent HTTP connections to random.org, on behalf of every node in the cluster. It's easy to imagine a situation where several RandomOrgBuffer instances are sending FetchFromRandomOrg message at the same time, beginning several concurrent HTTP connections. In order to avoid this situation we implement already known technique of queueing requests in actor if one request wasn't yet finished:case class FetchFromRandomOrg(batchSize: Int)This time pay attention to
case class RandomOrgServerResponse(randomNumbers: List[Int])
class RandomOrgClient extends Actor {
val client = new AsyncHttpClient()
val waitingForReply = new mutable.Queue[(ActorRef, Int)]
override def postStop() {
client.close()
}
def receive = LoggingReceive {
case FetchFromRandomOrg(batchSize) =>
waitingForReply += (sender -> batchSize)
if (waitingForReply.tail.isEmpty) {
sendHttpRequest(batchSize)
}
case response: RandomOrgServerResponse =>
waitingForReply.dequeue()._1 ! response
if (!waitingForReply.isEmpty) {
sendHttpRequest(waitingForReply.front._2)
}
}
private def sendHttpRequest(batchSize: Int) {
val url = "https://www.random.org/integers/?num=" + batchSize + "&min=0&max=65535&col=1&base=10&format=plain&rnd=new"
client.prepareGet(url).execute(new RandomOrgResponseHandler(self))
}
}
private class RandomOrgResponseHandler(notifyActor: ActorRef) extends AsyncCompletionHandler[Unit]() {
def onCompleted(response: Response) {
val numbers = response.getResponseBody.lines.map(_.toInt).toList
notifyActor ! RandomOrgServerResponse(numbers)
}
}
waitingForReply queue. When a request to fetch random numbers from remote web service comes in, either we initiate new connection (if the queue doesn't contain no-one except us). If there are other actors awaiting, we must politely put ourselves in the queue, remembering who requested how many numbers (waitingForReply += (sender -> batchSize)). When a reply arrives, we take the very first actor from the queue (who waits for the longest amount of time) and initiate another request on behalf of him.Unsurprisingly there is no multithreading or synchronization code. However it's important not to break encapsulation by accessing its state outside of
receive method. I made this mistake by reading waitingForReply queue inside onCompleted() method. Because this method is called asynchronously by HTTP client worker thread, potentially we can access our actors state from two threads at the same time (if it was handling some message in receive at the same time). That's the reason why I decided to extract HTTP reply callback into a separate class, not having implicit access to an actor. This is much safer as access to actor's state is guarded by the compiler itself. This is the last part of our Discovering Akka series. Remember that the complete source code is available on GitHub.
This was a translation of my article "Poznajemy Akka: zdalni aktorzy" originally published on scala.net.pl.Tags: akka, scala