Benchmarking impact of batching in Hystrix
generateIntegers(1)):public interface RandomOrgClient {
RandomIntegers generateIntegers(int howMany);
}
As you can see this method can easily fetch more than one number. You might wonder why it returns some fancy RandomIntegers class rather than, say List<Integer>? Well, a list of integers is just a data structure, it doesn't represent any business concept, while *random integers* leaves no room for speculation. Still unsurprisingly the implementation is just a wrapper/decorator over a list:public class RandomIntegers extends AbstractList<Integer> {
private final ImmutableList<Integer> values;
public RandomIntegers(Collection<Integer> values) {
this.values = ImmutableList.copyOf(values);
}
@Override
public Integer get(int index) {
return values.get(index);
}
@Override
public int size() {
return values.size();
}
public RandomIntegers take(int n) {
return new RandomIntegers(values.subList(0, n));
}
public RandomIntegers drop(int n) {
return new RandomIntegers(values.subList(n, values.size()));
}
}
This immutable value object has two extra methods take(n) and drop(n) to split it. We will use them in the future. To avoid unexpected latency and manage errors we wrap client inside Hystrix command:public class GenerateIntegersCmd extends HystrixCommand<RandomIntegers> {
private final RandomOrgClient randomOrgClient;
private final int howMany;
public GenerateIntegersCmd(RandomOrgClient randomOrgClient, int howMany) {
super(Setter
.withGroupKey(asKey("random.org"))
.andCommandKey(HystrixCommandKey.Factory.asKey("generateIntegers"))
.andThreadPoolPropertiesDefaults(
HystrixThreadPoolProperties.Setter()
.withCoreSize(100)
.withMaxQueueSize(100)
.withQueueSizeRejectionThreshold(100))
.andCommandPropertiesDefaults(
HystrixCommandProperties.Setter()
.withExecutionIsolationThreadTimeoutInMilliseconds(2000))
);
this.randomOrgClient = randomOrgClient;
this.howMany = howMany;
}
@Override
protected RandomIntegers run() throws Exception {
return randomOrgClient.generateIntegers(howMany);
}
}
We use an enormously big thread pool (100), Netflix claims 10-20 is enough in their cases, we'll see later how to fix it. Now imagine we have a simple endpoint that needs to call this API on each request:@RestControllerNow imagine
public class RandomController {
private final RandomOrgClient randomOrgClient;
@Inject
public RandomController(RandomOrgClient randomOrgClient) {
this.randomOrgClient = randomOrgClient;
}
@RequestMapping("/{howMany}")
public String random(@PathVariable("howMany") int howMany) {
final HystrixExecutable<RandomIntegers> generateIntsCmd =
new GenerateIntegersCmd(randomOrgClient, howMany);
final RandomIntegers response = generateIntsCmd.execute();
return response.toString();
}
}
random.org has an average of 500 ms latency (totally made up number, see here for real data). When load testing our simple application with 100 clients we can expect about 200 transactions per second with half a second average response time:

Collapsing (batching) is about collecting similar small requests into one bigger. This reduces downstream dependencies' load and network traffic. However this feature comes at a price of increased transaction time because before calling
random.org directly we must now wait a bit, just in case some other client wants to call random.org at the same time. The first step to batch requests is to implement HystrixCollapser:public class GenerateIntegersCollapser extends HystrixCollapser<RandomIntegers, RandomIntegers, Integer> {
private final int howMany;
private final RandomOrgClient randomOrgClient;
public GenerateIntegersCollapser(RandomOrgClient randomOrgClient, int howMany) {
super(withCollapserKey(HystrixCollapserKey.Factory.asKey("generateIntegers"))
.andCollapserPropertiesDefaults(Setter().withTimerDelayInMilliseconds(100))
.andScope(Scope.GLOBAL));
this.howMany = howMany;
this.randomOrgClient = randomOrgClient;
}
@Override
public Integer getRequestArgument() {
return howMany;
}
@Override
protected HystrixCommand<RandomIntegers> createCommand(Collection<CollapsedRequest<RandomIntegers, Integer>> collapsedRequests) {
final int totalHowMany = collapsedRequests
.stream()
.mapToInt(CollapsedRequest::getArgument)
.sum();
return new GenerateIntegersCmd(randomOrgClient, totalHowMany);
}
@Override
protected void mapResponseToRequests(RandomIntegers batchResponse, Collection<CollapsedRequest<RandomIntegers, Integer>> collapsedRequests) {
RandomIntegers ints = batchResponse;
for (CollapsedRequest<RandomIntegers, Integer> curRequest : collapsedRequests) {
final int count = curRequest.getArgument();
curRequest.setResponse(ints.take(count));
ints = ints.drop(count);
}
}
}
GenerateIntegersCollapser is used twice in Hystrix - first when a bunch of requests come in at roughly the same time. After configured window (100 ms in our example) all requests are taken together and Hystrix asks us to create one batch command (see: createCommand()). All we do is calculate how many random integers we need in total and ask for all of them in one go. Second time GenerateIntegersCollapser is used when batch response arrives and we need to split it back into individual, small requests. That's the responsibility of mapResponseToRequests(). See how we chop batchResponse into smaller pieces? First I used mind-bending implementation with reduce just to avoid mutability:collapsedRequests.stream().reduce(batchResponse, (leftInBatch, curRequest) -> {
final int count = curRequest.getArgument();
curRequest.setResponse(leftInBatch.take(count));
return leftInBatch.drop(count);
}, (x, y) -> {throw new UnsupportedOperationException("combiner not needed");});
This variant of Stream.reduce() is roughly equivalent to TraversableOnce.aggregate (z: ⇒ B) (seqop: (B, A) ⇒ B, combop: (B, B) ⇒ B): B) in Scala. But I have a problem with this smarty pants functional style - it's harder to read, isn't shorter and requires combiner parameter, that isn't even used in single thread (but API requires it...) So let's stick to simplicity over cleverness.One last remark is
Scope.GLOBAL. Without it collapsing would work only within one thread, e.g. HTTP request, rather than across the whole application. We definitely want global collapsing. Having collapser in place we can use it instead of normal command:final HystrixExecutable<RandomIntegers> generateIntsCollapser =So not much changes from client code perspective. Now let's benchmark a bit:
new GenerateIntegersCollapser(randomOrgClient, howMany);
final RandomIntegers response = generateIntsCollapser.execute();
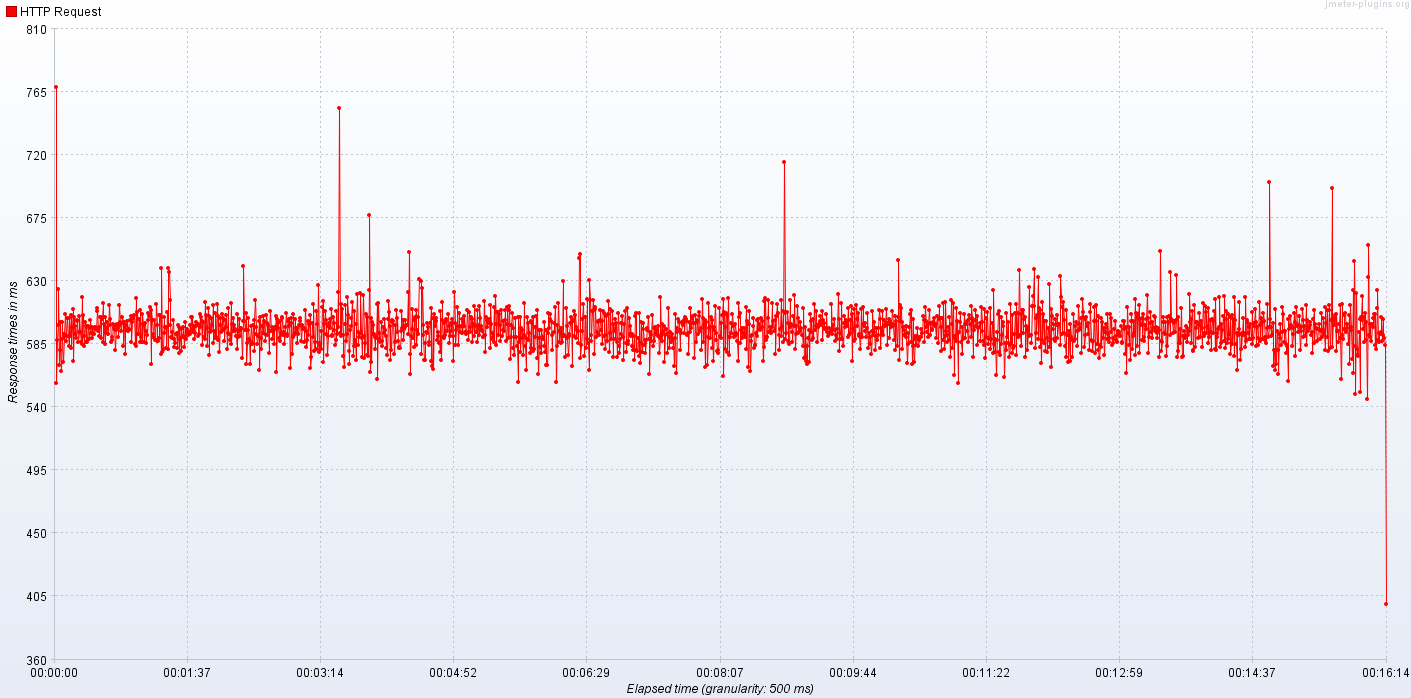

Ouch, this is quite disappointing. Average response time grew from 500 to 600 milliseconds. At the same time throughput measured in transactions per second (TPS, generated by 100 concurrent threads) dropped to about 160-170/s with significant variance. These numbers shouldn't really come as a surprise - enabling batching requires almost every request to wait a little bit, just in case another request comes by in the nearest future. Less stable measurements are also understandable - latency of each individual request depends on whether the collapsing window just opened or is about to close. OK, so what's the big deal, why do we bother with collapsing? Remember previous example - with 200 TPS we made 200 network calls and requests to external service. 100 concurrent clients meant 100 concurrent requests to backing service. The biggest win of batching/collapsing is reduction of downstream load, generated by our code. It means we put less load on our dependencies and flatten peaks. Just compare the number of queries we made to
random.org API with and without batching:

Tags: Hystrix, multithreading