CharBusters
10 Unicode myths
CharBusters
10 Unicode myths
काचं शक्नोम्यत्तुम् । नोपहिनस्ति माम् ॥
Μπορῶ νὰ φάω σπασμένα γυαλιὰ χωρὶς νὰ πάθω τίποτα 🇬🇷
ᛁᚳ᛫ᛗᚨᚷ᛫ᚷᛚᚨᛋ᛫ᛖᚩᛏᚪᚾ᛫ᚩᚾᛞ᛫ᚻᛁᛏ᛫ᚾᛖ᛫ᚻᛖᚪᚱᛗᛁᚪᚧ᛫ᛗᛖ᛬
⠊⠀⠉⠁⠝⠀⠑⠁⠞⠀⠛⠇⠁⠎⠎⠀⠁⠝⠙⠀⠊⠞⠀⠙⠕⠑⠎⠝⠞⠀⠓⠥⠗⠞⠀⠍⠑
Я можу їсти скло, і воно мені не зашкодить. 🇺🇦
მინას ვჭამ და არა მტკივა. 🇬🇪
Կրնամ ապակի ուտել և ինծի անհանգիստ չըներ։ 🇦🇲
నేను గాజు తినగలను మరియు అలా చేసినా నాకు ఏమి ఇబ్బంది లేదు 🇮🇳
איך קען עסן גלאָז און עס טוט מיר נישט װײ
ᐊᓕᒍᖅ ᓂᕆᔭᕌᖓᒃᑯ ᓱᕋᙱᑦᑐᓐᓇᖅᑐᖓ
ᠪᠢ ᠰᠢᠯᠢ ᠢᠳᠡᠶᠦ ᠴᠢᠳᠠᠨᠠ ᠂ ᠨᠠᠳᠤᠷ ᠬᠣᠤᠷᠠᠳᠠᠢ ᠪᠢᠰᠢ 🇲🇳
我能吞下玻璃而不伤身体。🇨🇳
أنا قادر على أكل الزجاج و هذا لا يؤلمني.

https://madhatters.me.uk/2009/07/16/health-warning-3/smoking-kills/
https://en.wikipedia.org/wiki/List_of_Unicode_characters

https://www.dogancanulker.com/noktali-ve-noktasiz-problemi/
- I don’t need to worry about Unicode
- 1 character = 1
byte - 1 character = 1
char - Java is UTF-16
- Unicode is unambiguous
- 1 character ≤ 1
int - 1 character ≤ 2
ints String.length()is useful- Whitespace is straightforward
- Upper case is simple
- Unicode is harmless
I don’t need to worry about Unicode
Myth 0

https://twitter.com/filipvanlaenen/status/1009397273351131136
History of IT
(or how we estimate badly)
Parkinson's Law
Work expands so as to fill the time available for its completion
Hofstadter's Law
It always takes longer than you expect, even when you take into account Hofstadter's Law

https://twitter.com/HPC_Guru/status/850698874457141248
IPv4
1978
The number of connected devices in 2021 is set to hit 46 billionSource: How Many IoT Devices Are There in 2022?
640 KiB
Bill Gates IBM, 1981
Source: Computer Memory: 640K Ought to be Enough for Anyone
Y2K38
512K problem

en.wikipedia.org/wiki/Border_Gateway_Protocol#Routing_table_growth
blog.thousandeyes.com/what-is-768k-day
GPS 2019
www.orolia.com/resources/blog/lisa-perdue/2018/gps-2019-week-rollover-what-you-need-knowASCII
1963
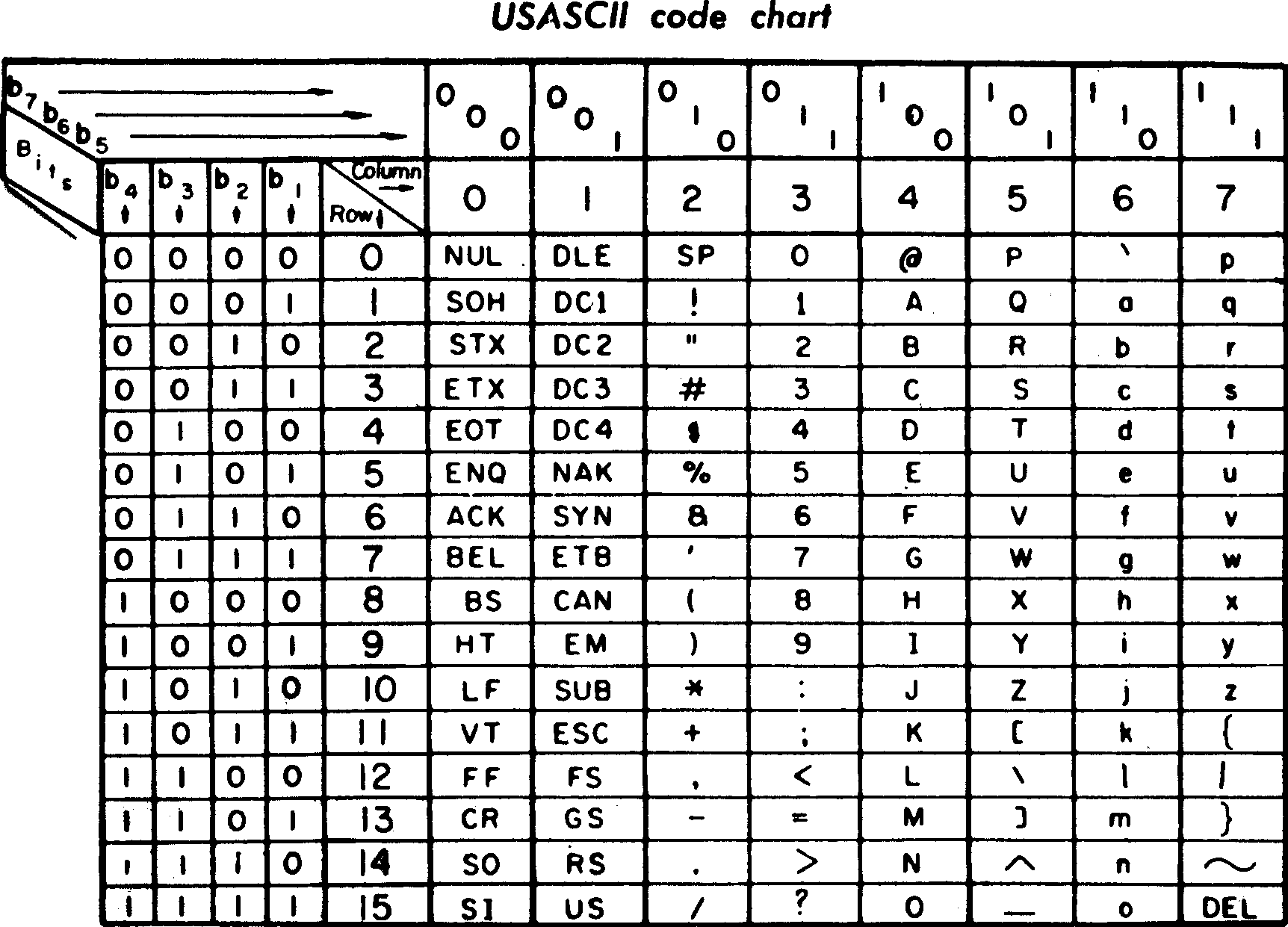
https://en.wikipedia.org/wiki/ASCII
1 character = 1 byte
Myth 1
Let’s talk about "ą"
ą
| ISO-8859-2 |
B1
|
| ISO 8859-13 |
E0
|
| ISO 8859-16 |
A2
|
| Windows-1250 |
B9
|
| CP775 |
D0
|
| CP852 |
A5
|
| Mazovia |
86
|
🇵🇱
| ą | ć | ę | ł | ń | ó | ś | ź | ż |
| Ą | Ć | Ę | Ł | Ń | Ó | Ś | Ź | Ż |
🇨🇿
| á | é | í | ó | ú | ý | č | ď | ě | ň | ř | š | ť | ž | ů |
| Á | É | Í | Ó | Ú | Ý | Č | Ď | Ě | Ň | Ř | Š | Ť | Ž | Ů |
🇫🇷
| ù | û | ü | ÿ | à | â | æ | ç | é | è | ê | ë | ï | î | ô | œ |
| Ù | Û | Ü | Ÿ | À | Æ | Ç | É | È | Ê | Ë | Ï | Î | Ô | Œ |
🇷🇺
| а | б | в | г | д | е | ё | ж | з | и | й | к | л | м | н | о | п |
| А | Б | В | Г | Д | Е | Ё | Ж | З | И | Й | К | Л | М | Н | О | |
| П | р | с | т | у | ф | х | ц | ч | ш | щ | ъ | ы | ь | э | ю | я |
| Р | С | Т | У | Ф | Х | Ц | Ч | Ш | Щ | Ъ | Ы | Ь | Э | Ю | Я |
🇩🇪 🇬🇷 🇪🇸
Unicode 1.0
modern [characters], whose number is undoubtedly far below 214 = 16 384
1988
Unicode code points
a = U+0061 = 97
å = U+00E5 = 229
ą = U+0105 = 261
鑫= U+946B = 37995
1 character = 1 char
Myth 2
[...] undoubtedly far below 214 = 16 384
1988
🇨🇳
讓我來! 让我来!
https://www.quora.com/How-do-you-say-hold-my-beer-in-Chinese
CJK
Almost 93 thousand characters in Unicode 14.0
Source: CJK Unified Ideographs𝄞
U+1D11E (119 070)
String
"𝄞".codePointAt(0)
//119070
Unicode 2.0
1996
| a | U+0061 |
| ą | U+0105 |
| 鑫 | U+946B |
| 𝄞 | U+1D11E |
Correct Java type for one character is...?
bytecharintString
String
codePointAt(int) : int
codePoints() : IntStream
codePointCount(int, int) : int
Unicode
vs
UTF-*
UTF-7, UTF-8
UTF-16 [BOM | LE | BE]
UTF-32 [BOM | LE | BE]
a
U+0061
| UTF-8 | 61 |
| UTF-16 | 00 61 |
| UTF-32 | 00 00 00 61 |
ą
U+0105
| UTF-8 | C4 85 |
| UTF-16 | 01 85 |
| UTF-32 | 00 00 01 05 |
鑫
U+946B
| UTF-8 | E9 91 AB |
| UTF-16 | 94 6B |
| UTF-32 | 00 00 94 6B |
𝄞
U+1D11E
| UTF-8 | F0 9D 84 9E |
| UTF-16 | D8 34 DD 1E |
| UTF-32 | 00 01 D1 1E |
Surrogate pairs
𝄞
- 1 code point
- 2 code units (a pair)
🤔
"𝄞".length() == 2
C#/Java/JS:
"(𝄞)".Substring(0, 2)
(?
var life = "🏭" + "🏖";
StringBuilder rev = new StringBuilder();
for (int i = life.length() - 1; i >= 0; i--)
rev.append(life.charAt(i));
var life = "🏭🏖";
"?🏭?"
C#
char[] array = "🇬🇧".ToCharArray() ;
Array.Reverse(array) ;
Console.WriteLine(new string(array));
????
Java is UTF-16
Myth 3
Java 8
private final char value[];
Java 9+
private final byte[] value;
Java 9+
public int indexOf(int ch, int fromIndex) {
return isLatin1()
? StringLatin1.indexOf(value, ch, fromIndex)
: StringUTF16.indexOf(value, ch, fromIndex);
}
String.getBytes()
blog.thetaphi.de/2012/07/default-locales-default-charsets-and.html
UTF-8 by default
JEP 400: UTF-8 by DefaultUnicode is unambiguous
Myth 4
"ą".equals("ą")
Little tail
| ą | Latin Small Letter A with Ogonek | U+0105 |
| a | Latin Small Letter A | U+0061 |
| ̨ | Combining Ogonek | U+0328 |
Quoting Wikipedia:
The ogonek ([...] "little tail", diminutive of ogon)
Normalizer.normalize("ą", Form.NFKC)
java.text
1 character ≤ 1 int
Myth 5
Let’s talk about emoji
https://www.dailymail.co.uk/femail/article-4794964/World-s-emoji-translator-ridiculed-Twitter.html

http://curlicuecal.tumblr.com/post/175362924100/an-entomologist-rates-ant-emojis
🇵🇱
🇵+🇱
🇵🇱
| 🇵 | 00 01 F1 F5 |
| 🇱 | 00 01 F1 F1 |
- 2 code points
- 4 code units
Ruby
$ irb
2.7.2 :001 > "abc".reverse!
=> "cba"
2.7.2 :002 > "🇬🇧".reverse!
=> "🇧🇬"
🇬 🇧 vs. 🇧 🇬
C#
char[] array = "🇬🇧".ToCharArray() ;
Array.Reverse(array) ;
Console.WriteLine(new string(array));
????
👧🏽
| 👧 | 00 01 F4 67 |
| 🏾 | 00 01 F3 FE |
| 👧🏽 | 00 01 F4 67 00 01 F3 FE |
🏻 🏼 🏽 🏾 🏿
1 character ≤ 2 ints
Myth 6
👩🏾🚀
| 👩 | 00 01 F4 69 |
| 🏾 | 00 01 F3 FE |
| ZWJ | 20 0D |
| 🚀 | 00 01 F6 80 |
👨👩👧👦
| 👨 | 00 01 F4 68 |
| ZWJ | 20 0D |
| 👩 | 00 01 F4 69 |
| ZWJ | 20 0D |
| 👧 | 00 01 F4 67 |
| ZWJ | 20 0D |
| 👦 | 00 01 F4 66 |
https://twitter.com/relizarov/status/1128347860263669761
String.length() is useful
Myth 7
public int length()
Returns the length [...] equal to the number of Unicode code units in the string.https://docs.oracle.com/en/java/javase/11/docs/api/java.base/java/lang/String.html#length()
Code unit 😱
The minimal bit combination that can represent a unit of encoded text.
"a".length() // 1
"ą".length() // 1
"ą".length() // 2
"𝄞".length() // 2
"👰".length() // 2
"🇵🇱".length() // 4
"👩🏾🚀".length() // 7
"👨👩👧👦".length() // 11
"🏴".length() // 14
"T̢̗̮͉͈̠̣͆͆̎͐̌͒͢ȍ̵͑̾͒͂͛̄̔͢҉̡̦͙͎̱̹͍͎͖̪̮̙̪͔̺͕̞̰̤̯m̍ͩ̓͋ͫ̑҉̵̷͓̦̩̭̗̩̫̺e̵̦̫̭̫̬͉̞̪̹̓̆̈́͊̂̃̀͡ǩ̸̴̢̛̫̦̬̪̘̱̖̼̺͕͇͕̞͓̮̭̯ͣ̌̂̏ͨͤͬ͛̏̋̉̀".length()
119
by Zalgo
https://developer.twitter.com/en/docs/basics/counting-characters.html
What is character?
- Code point
- Code unit
- Grapheme cluster
- Glyph
UTF
UTF is an [...] mapping from every Unicode code point [...] to a unique byte sequence
Whitespace is straightforward
Myth 8
How many different types of whitespaces there are?
All of them:
Space, tab, enter...
IntStream.rangeClosed(0, 0x10FFFF)
.filter(Character::isDefined)
.count();
| Java | Unicode | isDefined |
|---|---|---|
| 8 | 6.2 | 249 698 |
| 9/10 | 8.0 | 260 253 |
| 11 | 10.0 | 276 271 |
| 12 | 11.0 | 276 956 |
| 17 | 13.0 | 283 440 |
IntStream.rangeClosed(0, 0x10FFFF)
.filter(Character::isWhitespace)
.count();
| Java | isWhitespace |
|---|---|
| 8 | 26 |
| 9-17 | 25 |
Character.isWhitespace()
25 characters
String.trim()
32 characters
Pattern.compile("\\s")
6 characters
Upper case is simple
Myth 9
🇹🇷
🇹+🇷
"i".toUpperCase(tr_TR)
i → İ
Does Your Code Pass The Turkey Test?
- JDK-6220064 - REGRESSION: SSL connections fail with Turkish input locale
- JDK-6240755 - Swing rendering error for Turkish locale on XP look and feel
- JDK-6240963 - XSLT transforms broken in Turkish locale in JDK 1.5.0+
- JDK-6341798 - XMLDecoder fails when using Turkish Locale
- JDK-8023943 - Method description fix for String.toLower/UpperCase() methods
- JDK-4624534 - JarEntry.getCertificates() returns null on Turkish locale (tr_TR)
- JDK-6867345 - Turkish regional options cause NPE in sun.security.x509.AlgorithmId.algOID
- JDK-6972386 - issues with String.toLowerCase/toUpperCase
- JDK-6353473 - REGRESSION: NameGenerator.captialize doesn't work properly with Turkish locale
- JDK-8020037 - String.toLowerCase incorrectly increases length, if string contains \u0130 char
Unicode is harmless
Myth 10

- 'Trojan Source' attack method can hide bugs into open-source code
- Hacking GitHub's Auth with Unicode's Turkish Dotless 'I'
effective. Power لُلُصّبُلُلصّبُررً ॣ ॣh ॣ ॣ 冗
https://www.businessinsider.com/iphone-unicode-bug-crashes-messages-forces-devices-to-reboot-arabic-2015-5?IR=T
జ్ఞా
https://serhack.me/articles/crash-iphone-telugu-character-en
<⚫️>👈🏻
https://www.macworld.com/article/3271426/iphone-ipad/black-dot-unicode-bug-can-crash-messagesheres-how-to-fix-it.html
‏‎
https://blog.infobytesec.com/2018/05/remember-iphone-unicode-bug-android.html
Google search crashes when you ask "How many emojis on Apple"
https://www.bleepingcomputer.com/news/technology/google-search-crashes-when-you-ask-how-many-emojis-on-apple/
https://www.dogancanulker.com/noktali-ve-noktasiz-problemi/
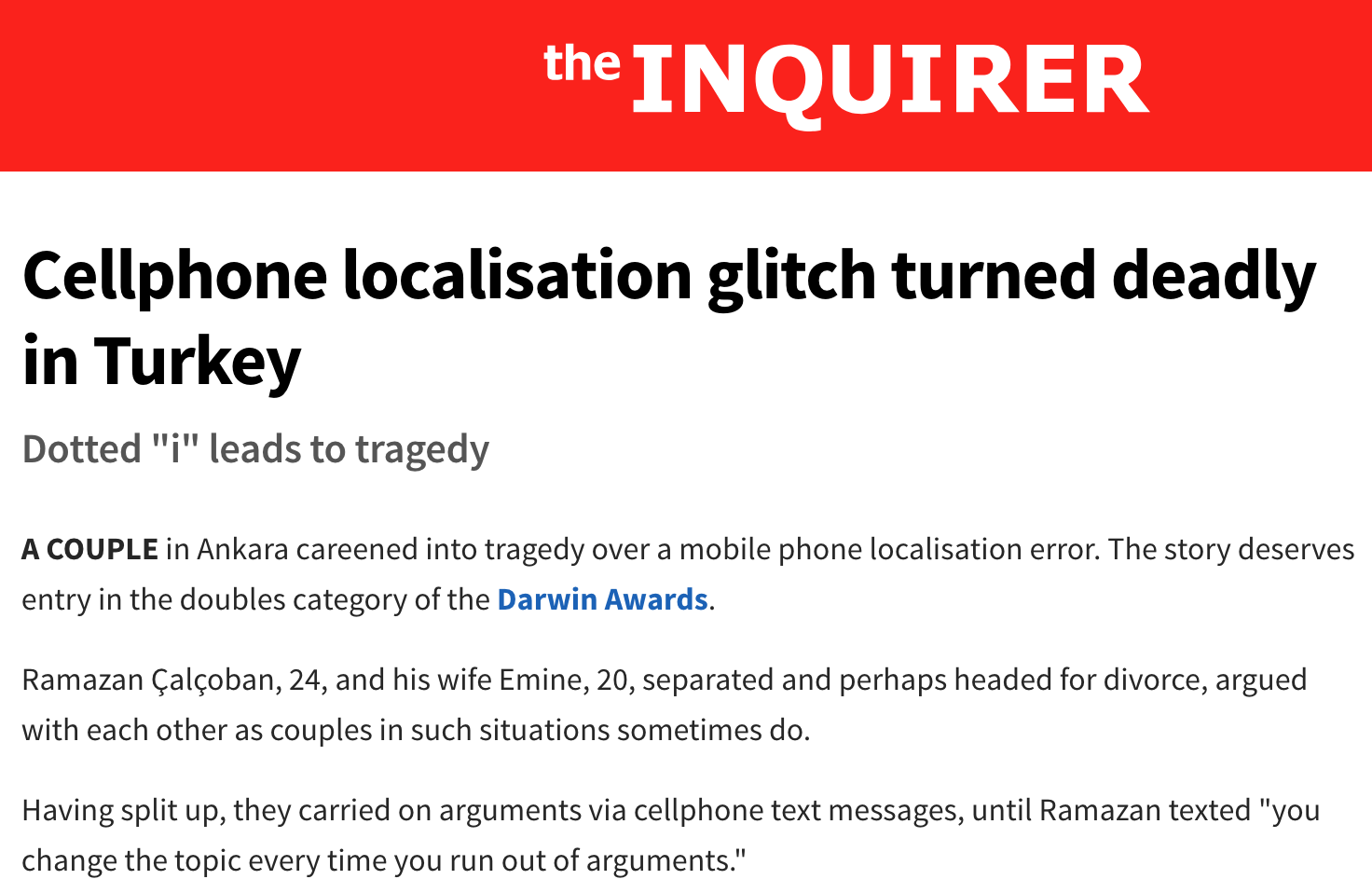 https://www.theinquirer.net/inquirer/news/1017243/cellphone-localisation-glitch
https://www.theinquirer.net/inquirer/news/1017243/cellphone-localisation-glitch
Zaten sen sıkışınca konuyu değiştiriyorsun.
Zaten sen sikişınce konuyu değiştiriyorsun.

sıkışınca ≠ sikişince
Zaten sen sıkışınca konuyu değiştiriyorsun.
Zaten sen sikişınce konuyu değiştiriyorsun.
sıkışınca ≠ sikişince
Anyhow, whenever you can't answer an argument, you change the subject.
Anyhow, whenever they are f***ing you, you change the subject.
Romanization
Zażółć gęślą jaźń
👇
Zazolc gesla jazn
Pangram
The quick brown fox jumps over the lazy dog
Jeżu klątw, spłódź Finom część gry hańb
Conclusions
Ińtërnâtiônàlizætión☃⛄️
https://mathiasbynens.be/notes/javascript-unicodeWhich encoding is the best?
It depends
UTF-8
UTF-8 is used by 97.7% of all the websites whose character encoding we knowUsage statistics of character encodings for websites
References
- utf8everywhere.org
- The Absolute Minimum Every Software Developer Absolutely, Positively Must Know About Unicode and Character Sets (No Excuses!)
- Should UTF-16 be considered harmful?
- Supplementary Characters in the Java Platform
- In MySQL, never use “utf8”. Use “utf8mb4”
- Why Can't You Reverse A String With a Flag Emoji?
- U+237C ⍼ RIGHT ANGLE WITH DOWNWARDS ZIGZAG ARROW
Thank you!
